
The book “The Black Swan” by Nassim Nicholas Taleb explores the concept of rare, highly improbable events with enormous impact on our world. Not surprisingly, this philosophy can also be applied in the world of technology and IT solutions such as data center or cybersecurity. In this article we explore how the concept of the Black Swan translates into IT and how we can manage risk in such a dynamic and ever-changing world.
What is a Black Swan in IT?
In IT, a Black Swan is a rare event, but with a major impact, that can negatively affect, partially or irreparably, the operations of a data center or an IT system serving a business activity, the responsibility in the case of a supplier being a double one. A rare event may be a cyber security incident, a critical failure of key equipment, an earthquake, flood or other natural disaster. It can also be a surprising innovation or breakthrough that completely revolutionizes the way things are done in the IT industry.
Risk management in the data center.
Risk management means minimizing losses and ensuring continuity, and this can only be achieved by building an IT ecosystem, the strategies that need to be applied are the following:
I. Redundancy:
Implementing redundancy in the infrastructure can help minimize the impact of major failures and consists of duplicate equipment, duplicate power supplies and duplicate internet connections, which is a primary and perhaps the most important advantage of outsourcing these types of services to a specialized company. If you find yourself in the situation of contracting such a specialized supplier, here is a checklist of requirements (to be ticked according to the budget allocated):
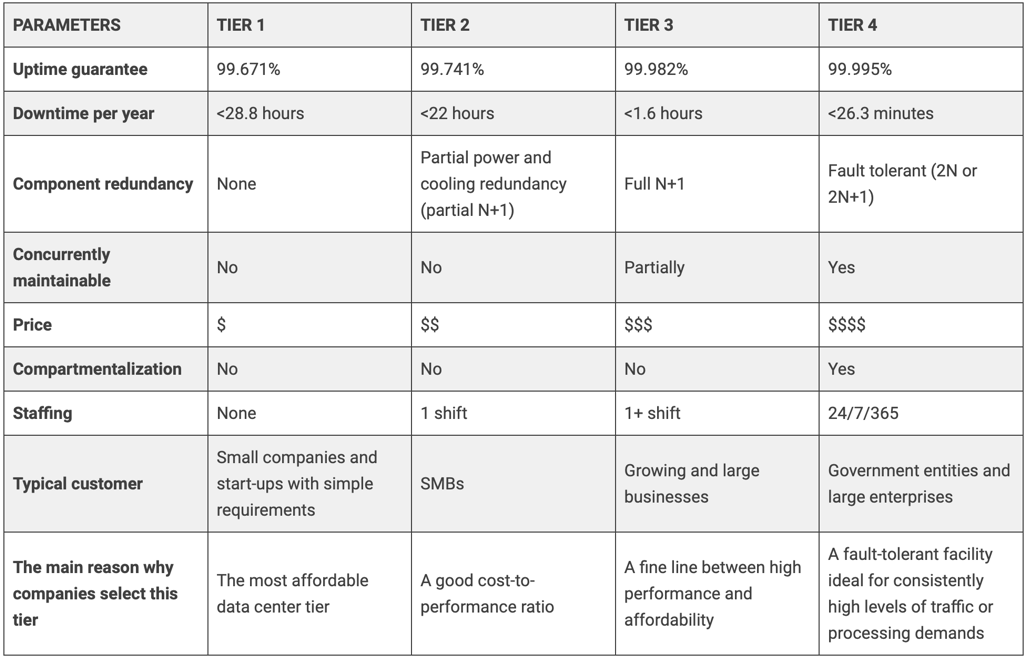
Uptime Institute TIER Standard
A data-center classification system is a way to evaluate and define the level of availability, redundancy and quality of services offered by a data-center. This rating system helps users to understand how reliable and robust the data centre is in providing services and to make comparisons between different facilities. One of the most popular classification systems is the TIER standard developed by the Uptime Institute. Here is a brief description of the TIER classification system for data centres:
Uptime Institute’s TIER standard:
TIER I: A Tier I data center has a simple architecture with no redundancy. Any of the critical components, such as power supply or cooling, do not have a full backup. Therefore, the data centre cannot ensure 24/7 availability.
TIER II: A Tier II data center adds some redundancy in critical components, such as power, but in general, planned maintenance operations still require services to be shut down. This level can ensure 99.741% availability (approximately 22 hours of downtime per year).
TIER III: The Tier III data center has a basic architecture with redundancy in all critical components. It includes two independent sources of power and cooling, allowing planned maintenance without shutting down services. This level can ensure 99.982% availability (approximately 1.6 hours of downtime per year).
TIER IV: The Tier IV data center offers the highest availability and reliability. It has full redundancy and duplicated components in all aspects. It can support planned maintenance or even component failure without affecting service availability. This level can ensure 99.995% availability (approximately 26.3 minutes of downtime per year).
II. Backup and recovery plans:
Creating well-defined and regularly tested backup and recovery plans can help you recover data and services quickly in the event of an unexpected incident. Make sure you have enough space allocated to store at least 3 versions of critical data.
Here are the main forms of back-up:
- Full backup: This type of backup involves copying all critical data to a separate storage medium. Full backup is useful to ensure quick data restoration in the event of a major failure, but can take up a significant amount of storage space.
- Incremental backup: incremental backup copies only new or changed data from the last backup, reducing the time needed to backup and the storage space required. Restoring data may be slower because it takes several backup iterations to restore the system to the desired state.
- Differential backup: Similar to incremental backup, but only copies data changed since the last full backup. This type of backup can be faster during restore than incremental backup, but requires more storage space.
- File-level backup: This type of backup copies individual files that are considered critical to the organization. It is useful when you need to recover only certain files and not the whole system.
- Image-level backup: This type of backup creates a complete image of the system or part of it, including the operating system, applications and data. It allows a quick restoration of the entire system in case of a major failure.
- Backup at virtual machine level: For organizations running virtual machines, this type of backup copies the entire virtual machine, including all its components. Allows quick and easy restoration of the entire virtual machine.
- Off-site backup: off-site backup involves storing backups in a physical location separate from the source location. This provides protection against natural disasters or other events that could affect the main data centre.
- Cloud backup: Cloud backup involves storing backups on cloud storage servers. It offers affordability and redundancy and is a popular solution for many organizations.
III. Prevention – constant monitoring and analysis:
Using advanced monitoring systems and predictive analytics can help identify potential problems before they become catastrophic. DON’T just rely on standard monitoring to confirm only what you want to see, but constantly seek an external IT audit to give you an objective view of your security level.
IV. Flexibility and adaptability:
Building a modular and scalable data center can allow you to adapt quickly to changes in the IT environment and minimize the risk of getting stuck in outdated technologies. DO NOT turn your experience into prejudice.
Innovation and opportunities in the Black Swan
In addition to risks, the Black Swan concept can also bring unexpected opportunities and innovation in IT. Unexpected breakthroughs and revolutionary technologies can radically change working paradigms and offer significant advantages.
Learning from previous Black Swan events
An important aspect of risk management in the data centre is learning from previous Black Swan events. Careful analysis of past incidents and how they were handled can provide valuable lessons for improving processes and safeguards.
In conclusion, Nassim Taleb’s book “The Black Swan” teaches us that, in the world of technology and IT solutions for the data center, we need to be aware of the existence of highly improbable events with a huge impact. By properly managing risk and adopting an attitude of adaptability and innovation, we can protect our IT infrastructure and turn these challenges into opportunities for growth and development. If you are looking for data center solutions, contact us here.


